3 Visualization Fundamentals
By the end of this chapter you should gain the following knowledge and practical skills.
3.1 Introduction
This chapter outlines the fundamentals of visualization design. It offers a position on what effective data graphics should do, before discussing the processes that take place when creating data graphics. A framework – a vocabulary and grammar – for supporting this process is presented which, combined with established knowledge on visual perception, helps describe, evaluate and create effective data graphics. Talking about a vocabulary and grammar of data and graphics may sound somewhat abstract. However, through an analysis of 2019 General Election results data, the chapter will demonstrate how these concepts are fundamental to visual data analysis.
3.2 Concepts
3.2.1 Effective data graphics
Data graphics take numerous forms and are used in many different ways by scientists, journalists, designers and many more. While the intentions of those producing them may vary, data graphics that are effective generally have the following characteristics:
- Expose complex structure, connections and comparisons that could not be achieved easily via other means;
- Are data rich, presenting many numbers in a small space;
- Reveal patterns at several levels of detail, from broad overview to fine structure;
- Are concise, emphasising dimensions of a dataset without extraneous details;
- Generate an aesthetic response, encouraging people to engage with the data or question.
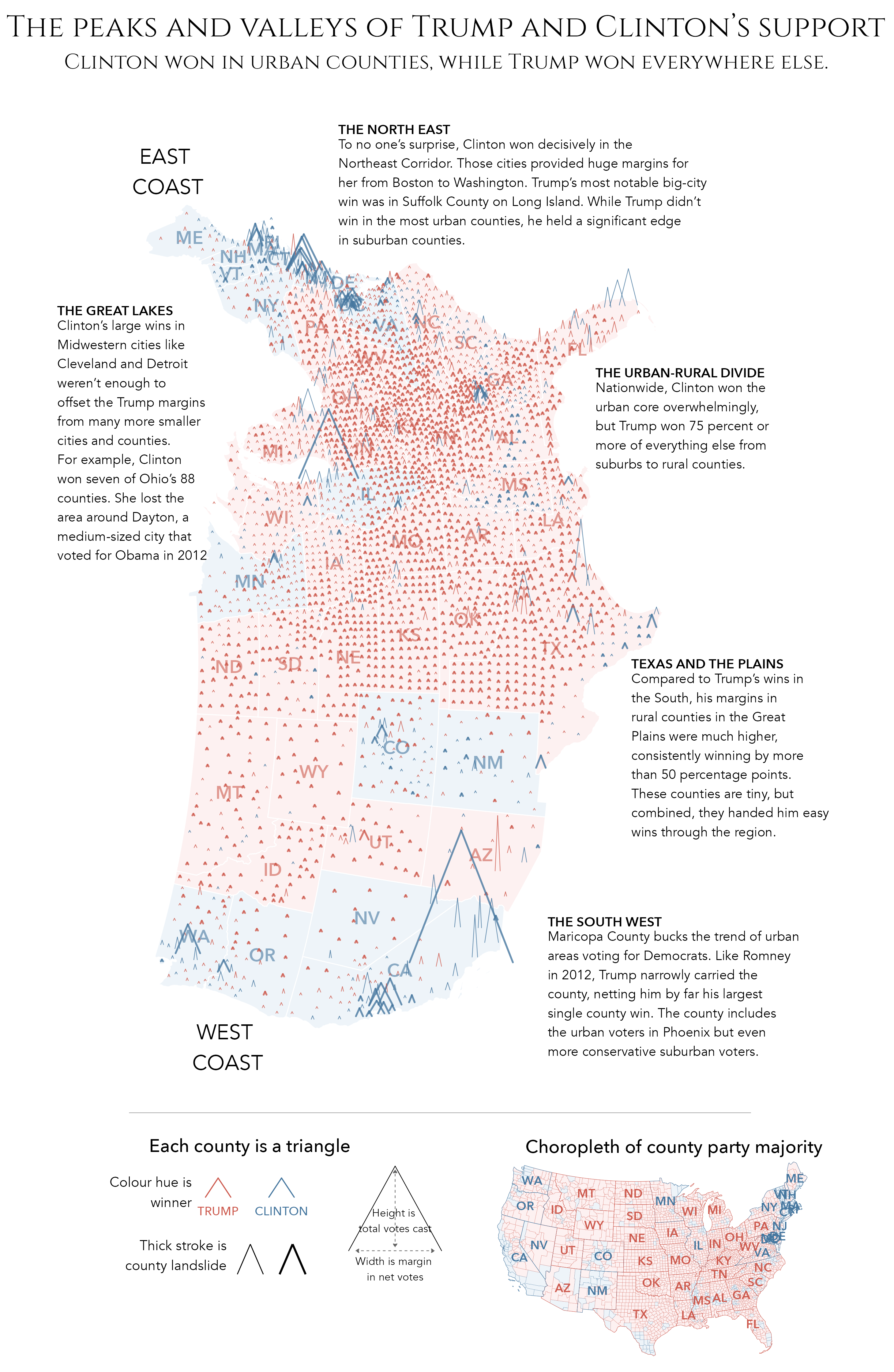
Consider the data graphic in Figure 3.1, which presents an analysis of the 2016 US Presidential Election, or the Peaks and Valleys of Trump and Clinton’s Support. The map is reproduced from an article in The Washington Post (Gamio and Keating 2016). Included in the bottom margin is a choropleth map coloured according to party majority, more standard practice for reporting county-level voting. Gamio and Keating’s (2016) graphic is clearly data rich, encoding many more data items than does the standard choropleth. It is not simply the data density that makes the graphic successful, however. There are careful design choices that help support comparison and emphasise complex structure. By varying the height of triangles according to the number of votes cast, the thickness according to whether or not the result for Trump/Clinton was a landslide and rotating the map 90 degrees, the very obvious differences between metropolitan, densely populated coastal counties that voted emphatically for Clinton and the vast number of suburban, provincial town and rural counties (everywhere else) that voted for Trump, are exposed.
3.2.2 Grammar of Graphics
Data graphics visually display measured quantities by means of the combined use of points, lines, a coordinate system, numbers, symbols, words, shading, and color.
Tufte (1983)
So the Washington Post graphic demonstrates a judicious mapping of data to visuals, underpinned by a close appreciation of the analysis context. The act of carefully considering how best to leverage visual systems given the available data and analysis priorities is key to designing effective data graphics. Leland Wilkinson’s Grammar of Graphics (1999) captures this process of turning data into visuals. Wilkinson’s (1999) thesis is that graphics can be described in a consistent way according to their structure and composition. This has obvious benefits for building visualization toolkits. If different chart types and combinations can be reduced to a common vocabulary and grammar, then the process of designing and generating graphics of different types can be systematised.
Wilkinson’s (1999) grammar separates the construction of data graphics into a series of components. Below are the components of the Layered Grammar of Graphics on which ggplot2 is based (Wickham 2010), adapted from Wilkinson’s (1999) original work. The components in Figure 3.2 are used to assemble ggplot2 specifications. Those to highlight at this stage are in emphasis : the data containing the variables of interest, the marks used to represent data and the visual channels through which variables are encoded.

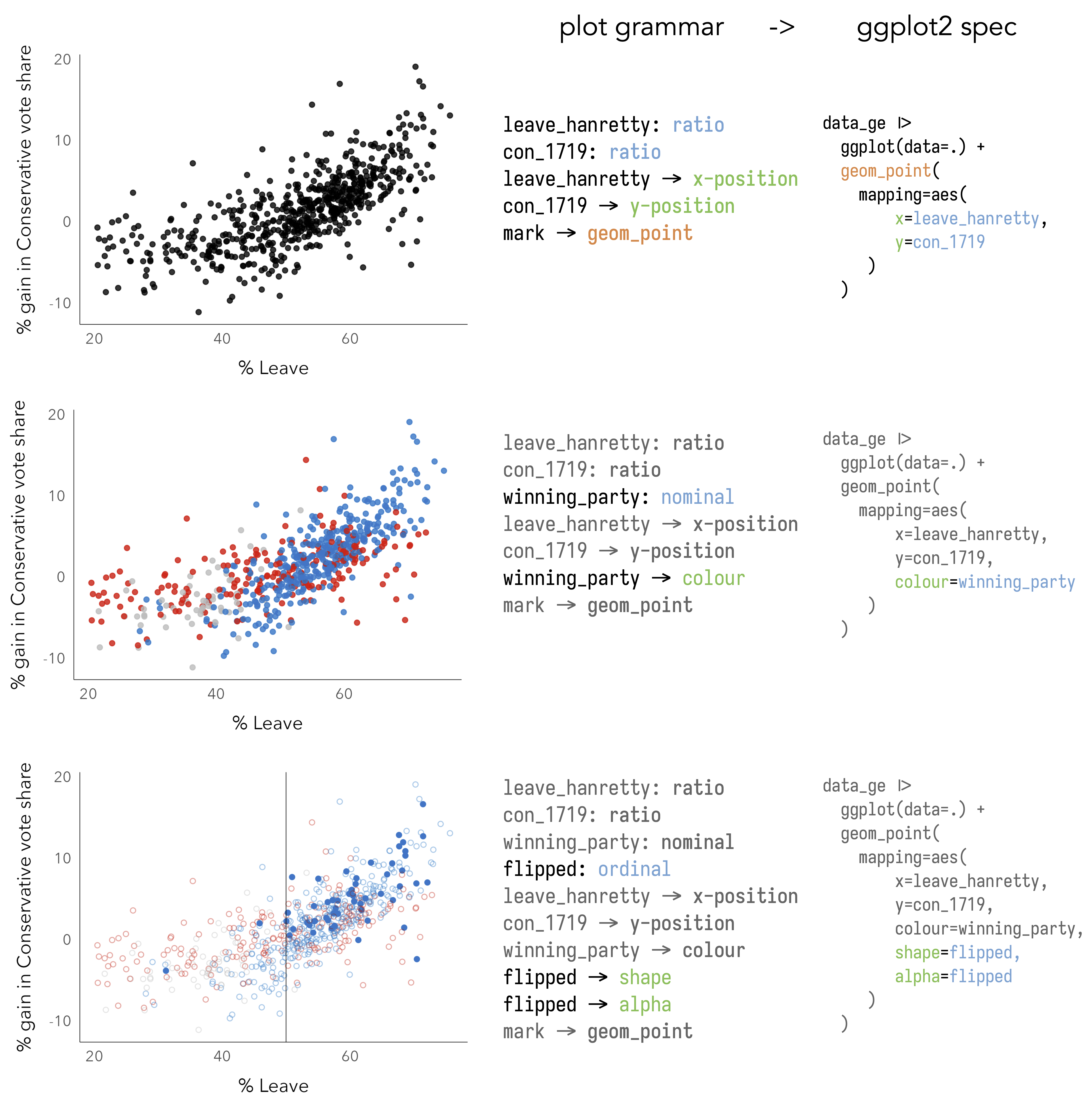
To demonstrate this, let’s generate some scatterplots based on the 2019 General Election data. Two variables worth exploring for association here are: con_1719, the change in Conservative vote share by constituency between 2017-2019, and leave_hanretty, the size of the Leave vote in the 2016 EU referendum, estimated at Parliamentary Constituency level (via Hanretty 2017).
In Figure 3.3 are three plots, accompanied by ggplot2 specifications used to generate them. Reading the graphics and the associated code, you should get a feel for how ggplot2 specifications are constructed:
- Start with a data frame, in this case 2019 General Election results for UK Parliamentary Constituencies. The data are passed to ggplot2 (
ggplot()) using the pipe operator (|>). Also at this stage, we consider the variables to encode and their measurement type – bothcon_1719andleave_hanrettyareratioscale variables. - Next is the encoding (
mapping=aes()), which determines how the data are to be mapped to visual channels . In a scatterplot, horizontal and vertical position varies in a meaningful way, in response to the values of a dataset. Here the values ofleave_hanrettyare mapped along the x-axis, and the values ofcon_1719are mapped along the y-axis. - Finally, we represent individual data items with marks using the
geom_point()geometry.
In the middle plot, the grammar is updated such that the points are coloured according to winning_party, a variable of type categorical nominal. In the bottom plot constituencies that flipped from Labour-to-Conservative between 2017-19 are emphasised by varying the shape (filled and not filled) and transparency (alpha) of points.
3.2.3 Marks and visual channels
In our descriptions marks was used as an alternative term for geometry and visual encoding channels as an alternative for aesthetics. We also paid special attention to the data types that were encoded. Marks are graphical elements such as bars, lines, points and ellipses that can be used to represent data items. In ggplot2 marks are accessed through the function layers prefaced with geom_*(). Visual channels are attributes such as colour, size and position that, when mapped to data, affect the appearance of marks in response to the values of a dataset. These attributes are controlled via the aes() (aesthetics) function in ggplot2.
Marks and channels are terms used routinely in Information Visualization, an academic discipline devoted to the study of data graphics, and most notably by Tamara Munzner (2014) in her textbook Visualization Analysis and Design. Munzner’s (2014) work synthesises over foundational research in Information Visualization and Cognitive Science testing how effective different visual channels are at supporting specific tasks. Figure 3.4 is adapted from Munzner (2014) and lists the main visual channels with which data might be encoded. The grouping and order of the figure is meaningful. Channels are grouped according to the tasks to which they are best suited and then ordered according to their effectiveness at supporting those tasks. The left grouping displays magnitude:order channels – those that are best suited to tasks aimed at quantifying data items. The right grouping displays identity:category channels – those that are most suited to supporting tasks that involve isolating and associating data items.
3.2.4 Evaluating designs
The effectiveness rankings of visual channels in Figure 3.4 are not simply based on Munzner’s preference. They are informed by detailed experimental work by Cleveland and McGill (1984), later replicated by Heer and Bostock (2010), which involved conducting controlled experiments testing people’s ability to make judgements from graphical elements. We can use Figure 3.4 to help make decisions around which data item to encode with which visual channel. This is particularly useful when designing data-rich graphics, where several data items are to be encoded simultaneously. Figure 3.4 also offers a low cost way of evaluating different designs against their encoding effectiveness.
To illustrate this, we can use Munzner’s ranking of channels to evaluate The Washington Post graphic discussed in Figure 3.1. Table 3.2 provides a summary of the encodings used in the graphic. US counties are represented using a peak-shaped mark. The key purpose of the graphic is to depict the geography of voting outcomes. The most effective quantitative channel – position on an aligned scale – is used to order the county marks with a geographic arrangement. With the positional channels taken, the two quantitative measures are encoded with the next highest ranked channel, length or 1D size: height varies according to number of total votes cast and width according to margin size. The marks are additionally encoded with two categorical variables: whether the county-level result was a landslide and also the winning party. Since the intention is to give greater visual saliency to counties that resulted in a landslide, this is an ordinal variable encoded with a quantitative channel: area / 2D size. The winning party, a categorical nominal variable, is encoded using colour hue.
| Data item | Type | Channel | Rank |
|---|---|---|---|
| Magnitude:Order | |||
| County location | interval | position in x,y | 1. quant |
| Total votes cast | ratio | length | 3. quant |
| Margin size | ratio | length | 3. quant |
| Is landslide | ordinal | area | 5. quant |
| Identity:Category | |||
| Winning party | nominal | colour hue | 2. cat |
Each of the encoding choices follow conventional wisdom in that data items are encoded using visual channels appropriate to their measurement level. Glancing down the “rank” column, the graphic has high effectiveness. While technically spatial region is the most effective channel for encoding nominal data, it is already in use as the marks are arranged by geographic position. Additionally, it makes sense to distinguish Republican and Democrat wins using the colours with which they are always represented. Given the fact that the positional channels represent geographic location, length to represent votes cast and vote margin, the only superior visual channel to 2D area that could be used to encode the landslide variable is orientation. There are very good reasons for not varying the orientation of the arrow marks. Most obvious is that this would undermine perception of length encodings used to represent the vote margin (width) and absolute vote size (height).
Visualization design and trade-offs
Data visualization design almost always involves trade-offs. A general principle is to identify and prioritise data and analysis tasks, then match the most effective encodings to the data and tasks that have the greatest priority. Less important data items and tasks therefore get less effective encodings. In practice, visualization design involves exercising more creative thinking – it is sometimes preferable to defy convensional wisdom in order to provoke some desired response. Either way, good visualization design is sensitive to this interplay between tasks, data and encoding.
3.2.5 Symbolisation
Symbolization is the process of encoding something with meaning in order to represent something else. Effective symbol design requires that the relationship between a symbol and the information that symbol represents (the referent) be clear and easily interpreted.
White (2017)
Implicit in the discussion above, and when making design decisions, is the importance of symbolisation. From the original Washington Post article, the overall pattern that can be discerned is of population-dense coastal and metropolitan counties voting Democrat – densely-packed, tall, wide and blue marks – contrasted with population-sparse rural and small town areas voting Republican – short, wide and red marks. The graphic evokes a distinctive landscape of voting behaviour, emphasised by its caption: “The peaks and valleys of Trump and Clinton’s support”.
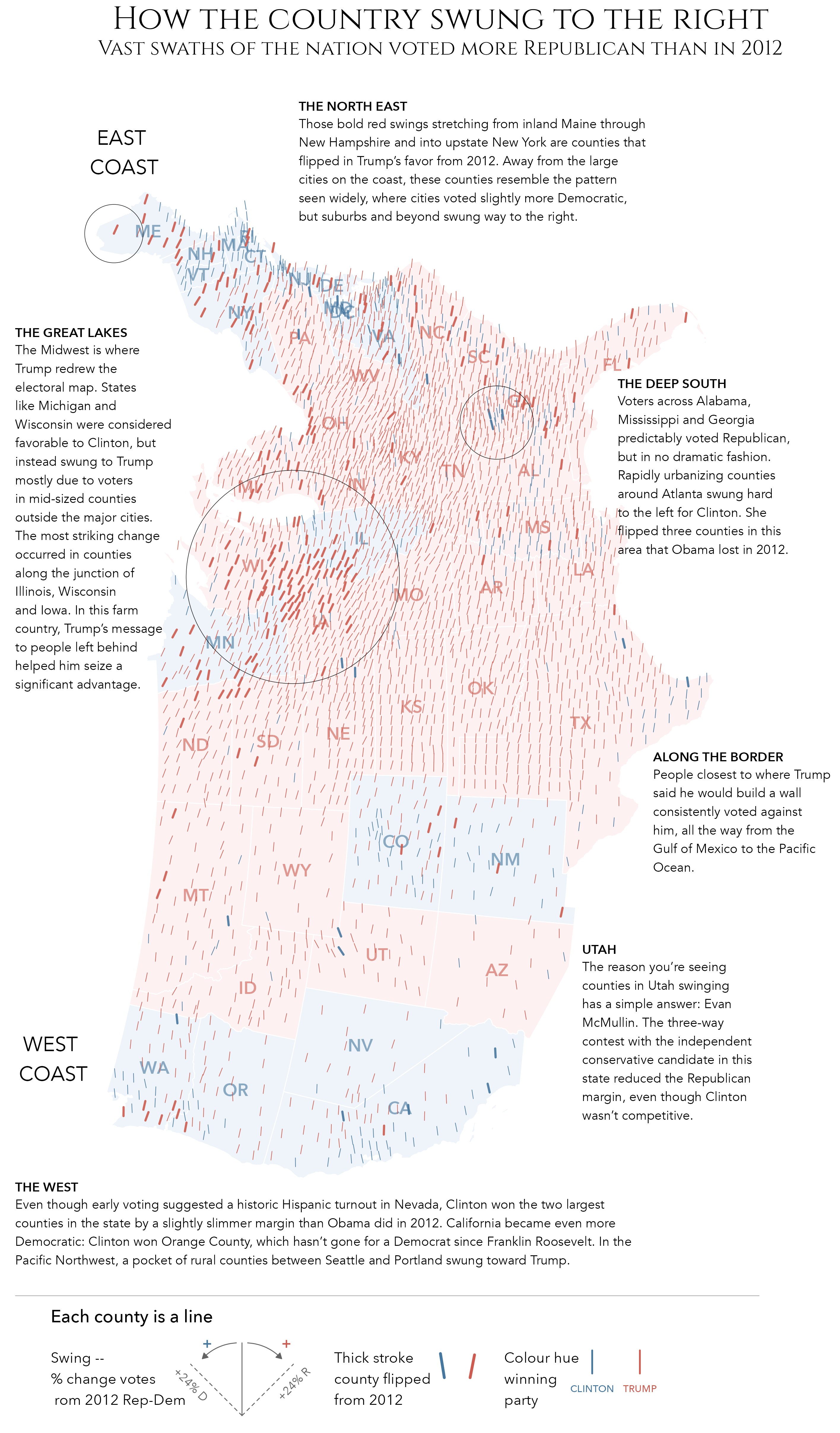
Symbolisation is used equally well in a variant of the graphic emphasising two-party Swing between the 2012 and 2016 elections (Figure 3.5). Each county is represented as a | mark. The Swing variable is then encoded by continuously varying mark angles: counties swinging Republican are angled to the right / ; counties swinging Democrat are angled to the left \ . Although angle is a less effective channel at encoding quantities than is length, there are obvious links to the political phenomena in the symbolisation – angled right for counties that moved to the right politically. There are further useful properties in this example. Since county voting is spatially auotocorrelated, we quickly assemble from the graphic dominant patterns of Swing to the Republicans (Great Lakes, rural East Coast), predictable Republican stasis (the Midwest) and more isolated, locally exceptional swings to the Democrats (rapidly urbanising counties in the deep South).
3.2.6 Colour
Colour is a very powerful visual channel. When considering how to encode data with colour, it is helpful to consider three properties:
- Hue: what we generally refer to as “colour” in everyday life – red, blue, green.
- Saturation: how much of a colour there is.
- Luminance/Brightness: how dark or light a colour is.
The ultimate rule is to use these properties of colour in a way that matches the properties of the data (Figure 3.6). Categorical nominal data – data that cannot be easily ordered – should be encoded using discrete colours with no obvious order; so colour hue. Categorical ordinal data – data whose categories can be ordered – should be encoded with colours that contain an intrinsic order; saturation or brightness (colour value) allocated into perceptually-spaced gradients. Quantitative data – data that can be ordered and contain values on a continuous scale – should also be encoded with saturation or brightness, expressed on a continuous scale. As we will discover shortly, these principles are applied by default in ggplot2, along with access to perceptually valid schemes (e.g. Harrower and Brewer 2003).

3.3 Techniques
The technical component to this chapter analyses data from the 2019 UK General Election, reported at Parliamentary Constituency level. After importing and describing the dataset, we will generate data graphics that expose patterns in voting behaviour.
- Download the
03-template.qmd2 file for this chapter and save it to yourvis4sdsproject. - Open your
vis4sdsproject in RStudio and load the template file by clickingFile>Open File ...>03-template.qmd.
3.3.1 Import
The template file lists the required packages – tidyverse and sf – and links to the 2019 UK General Election dataset, stored on the book’s accompanying data repository. These data were initially collected via the parlitools R package, which is no longer maintained.
The data frame of 2019 UK General Election data is called bes_2019. This stores results data released by the House of Commons Library (Uberoi, Baker, and Cracknell 2020). We can get a quick overview with a call to glimpse(<dataset-name>). bes_2019 has 650 rows, one for each parliamentary constituency, and 118 columns. In the columns are variables reporting vote numbers and shares for the main political parties for the 2019 and 2017 General Elections, as well as names and codes (IDs) for each constituency and the local authority, region and country in which they are contained.
We will replicate some of the visual data analysis in Beecham (2020). For this we need to calculate an additional variable, Butler Swing (Butler and Van Beek 1990): the average change in share of the vote won by two parties contesting successive elections. Code for calculating this variable, named swing_con_lab, is in the 03-template.qmd. The only other dataset to load is a .geojson file containing simplified geometries of constituencies, originally from ONS Open Geography Portal. This is a special class of data frame containing a Simple Features (Pebesma 2018) geometry column.
3.3.2 Summarise
You may be familiar with the result of the 2019 General Election, a landslide Conservative victory that confounded expectations. To start, we can quickly compute some summary statistics around the vote. In the code below, we count the number of seats won and overall vote share by party. For the vote share calculation, the code is a little more elaborate than we might wish at this stage. We need to reshape the data frame using pivot_wider() such that each row represents a vote for a party in a constituency. From here the vote share for each party can be easily computed.
# Number of constituencies won by party.
bes_2019 |>
group_by(winner_19) |>
summarise(count=n()) |>
arrange(desc(count))
## # A tibble: 11 x 2
## winner_19 count
## <chr> <int>
## 1 Conservative 365
## 2 Labour 202
## 3 Scottish National Party 48
## 4 Liberal Democrat 11
## 5 Democratic Unionist Party 8
## 6 Sinn Fein 7
## 7 Plaid Cymru 4
## 8 Social Democratic & Labour Party 2
## 9 Alliance 1
## 10 Green 1
## 11 Speaker 1
# Share of vote by party.
bes_2019 |>
# Select cols containing vote counts by party.
select(
constituency_name, total_vote_19,
con_vote_19:alliance_vote_19, region
) |>
# Pivot to make each row a vote for a party in a constituency.
pivot_longer(
cols=con_vote_19:alliance_vote_19,
names_to="party", values_to="votes"
) |>
# Use some regex to pull out party name.
mutate(party=str_extract(party, "[^_]+")) |>
# Summarise over parties.
group_by(party) |>
# Calculate vote share for each party.
summarise(vote_share=sum(votes, na.rm=TRUE)/sum(total_vote_19)) |>
# Arrange parties descending on vote share.
arrange(desc(vote_share))
## # A tibble: 12 x 2
## party vote_share
## <chr> <dbl>
## 1 con 0.436
## 2 lab 0.321
## 3 ld 0.115
## 4 snp 0.0388
## 5 green 0.0270
## 6 brexit 0.0201
## 7 dup 0.00763
## 8 sf 0.00568
## 9 pc 0.00479
## 10 alliance 0.00419
## 11 sdlp 0.00371
## 12 uup 0.00291While the Conservative party held 56% of constituencies in 2019 election, they won only 44% of the vote. The equivalent figures for Labour were 31% and 32% respectively. And although the Conservatives gained many more constituencies than they did in 2017 (when they won just 317, 49% of constituencies) their vote share hardly shifted between those elections – in 2017 the Conservative vote share was 43%. This fact is interesting as it may suggest some movement in where the Conservative party gained its majorities in 2019.
Below are some summary statistics computed over the newly created swing_con_lab variable. As the Conservative and Labour votes are negligible in Northern Ireland, it makes sense to focus on Great Britain for our analysis of Conservative-Labour Swing, and so the first step in the code is to create a new data frame filtering out Northern Ireland.
data_gb <- bes_2019 |>
filter(region != "Northern Ireland") |>
# Also recode to 0 Chorley and Buckingham, incoming/outgoing speaker.
mutate(
swing_con_lab=if_else(
constituency_name %in% c("Chorley", "Buckingham"), 0,
0.5*((con_19-con_17)-(lab_19-lab_17))
)
)
data_gb |>
summarise(
min_swing=min(swing_con_lab),
max_swing=max(swing_con_lab),
median_swing=median(swing_con_lab),
num_swing=sum(swing_con_lab>0),
num_landslide_con=sum(con_19>50, na.rm=TRUE),
num_landslide_lab=sum(lab_19>50, na.rm=TRUE)
)
## # A tibble: 1 x 6
## min_swing max_swing median_swing num_swing num_land_con num_land_lab
## <dbl> <dbl> <dbl> <int> <int> <int>
## 1 -6.47 18.4 4.44 599 280 1203.3.3 Plot distributions
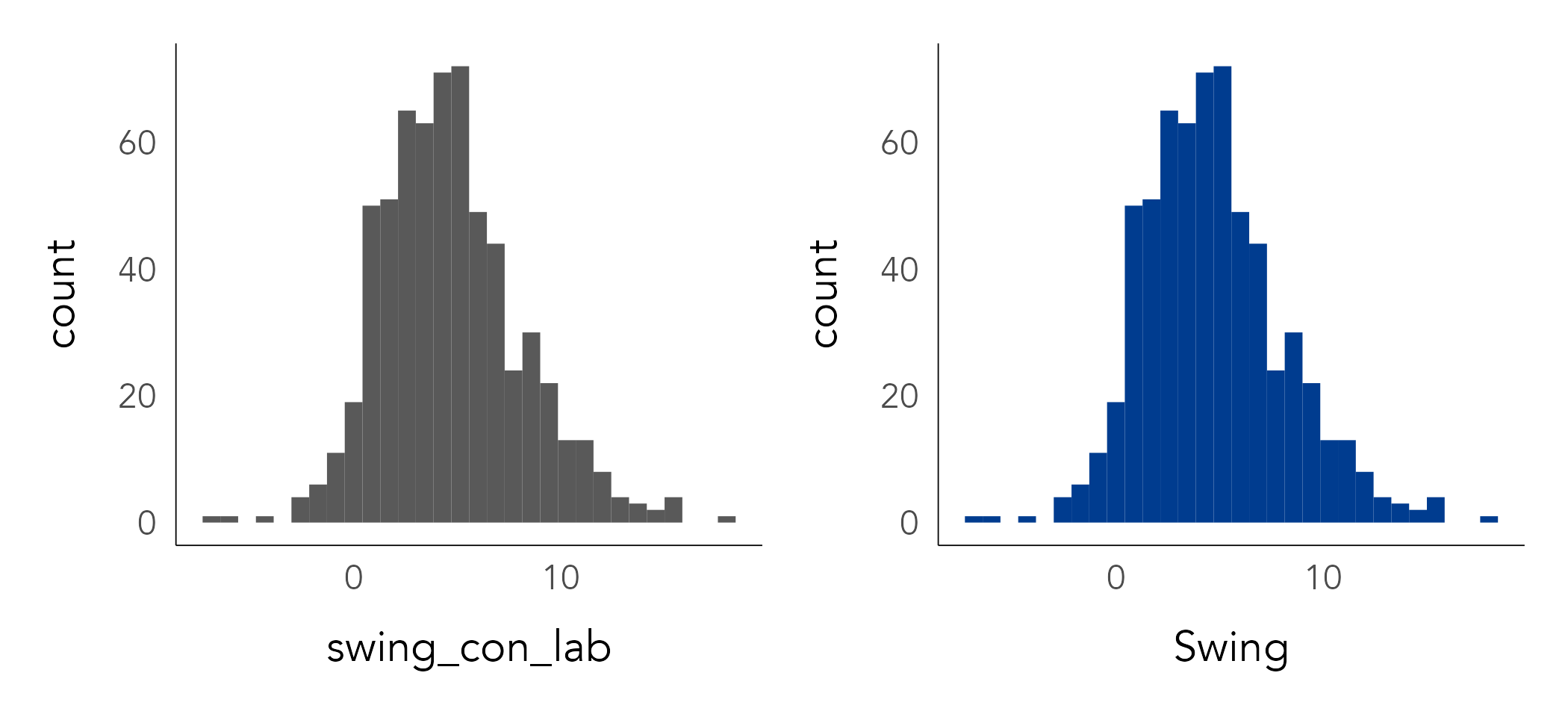
Let’s start with ggplot2 specifications by plotting some of these variables. Below is the code for plotting a histogram of the Swing variable.
data_gb |>
ggplot(mapping=aes(swing_con_lab)) +
geom_histogram()A reminder of the general form of a ggplot2 specification:
- Start with some data:
data_gb. - Define the encoding:
mapping=aes()into which we pass theswing_con_labvariable. - Specify the marks to be used:
geom_histogram()in this case.
Different from the scatterplot example, there is more happening in the internals of ggplot2 when creating a histogram. The Swing variable is partitioned into bins, and observations in each bin are counted. The x-axis (bins) and y-axis (counts by bin) are derived from the swing_con_lab variable.
By default the histogram’s bars are given a grey colour. To set them to a different colour, add a fill= argument to geom_histogram(). In the code block below, colour is set using hex codes. The term set, not map or encode, is used for principled reasons. Any part of a ggplot2 specification that involves encoding data – mapping a data item to a visual channel – should be specified through the mapping=aes() argument. Anything else, for example changing the default colour, thickness and transparency of marks, needs to be set outside of this argument.
data_gb |>
ggplot(mapping=aes(swing_con_lab)) +
geom_histogram(fill="#003c8f") +
labs(x="Swing", y="count") You will notice that different elements of a ggplot2 specification are added (+) as layers. In the example above, the additional layer of labels (labs()) is not intrinsic to the graphic. However, often you will add layers that do affect the graphic itself. For example, the scaling of encoded values (e.g. scale_*_continuous()) or whether the graphic is to be conditioned on another variable to generate small multiples for comparison (e.g. facet_*()). Adding a call to facet_*(), we can compare how Swing varies by region (Figure 3.8). The plot is annotated with the median value for Swing (4.4) by adding a vertical line layer (geom_vline()) set with an x-intercept at this median value. From this, there is some evidence of a regional geography to the 2019 vote: London and Scotland are distinctive in containing relatively few constituencies swinging greater than the expected midpoint; North East, Yorkshire & The Humber, and to a lesser extent West and East Midlands, appear to show the largest relative number of constituencies swinging greater than the midpoint.
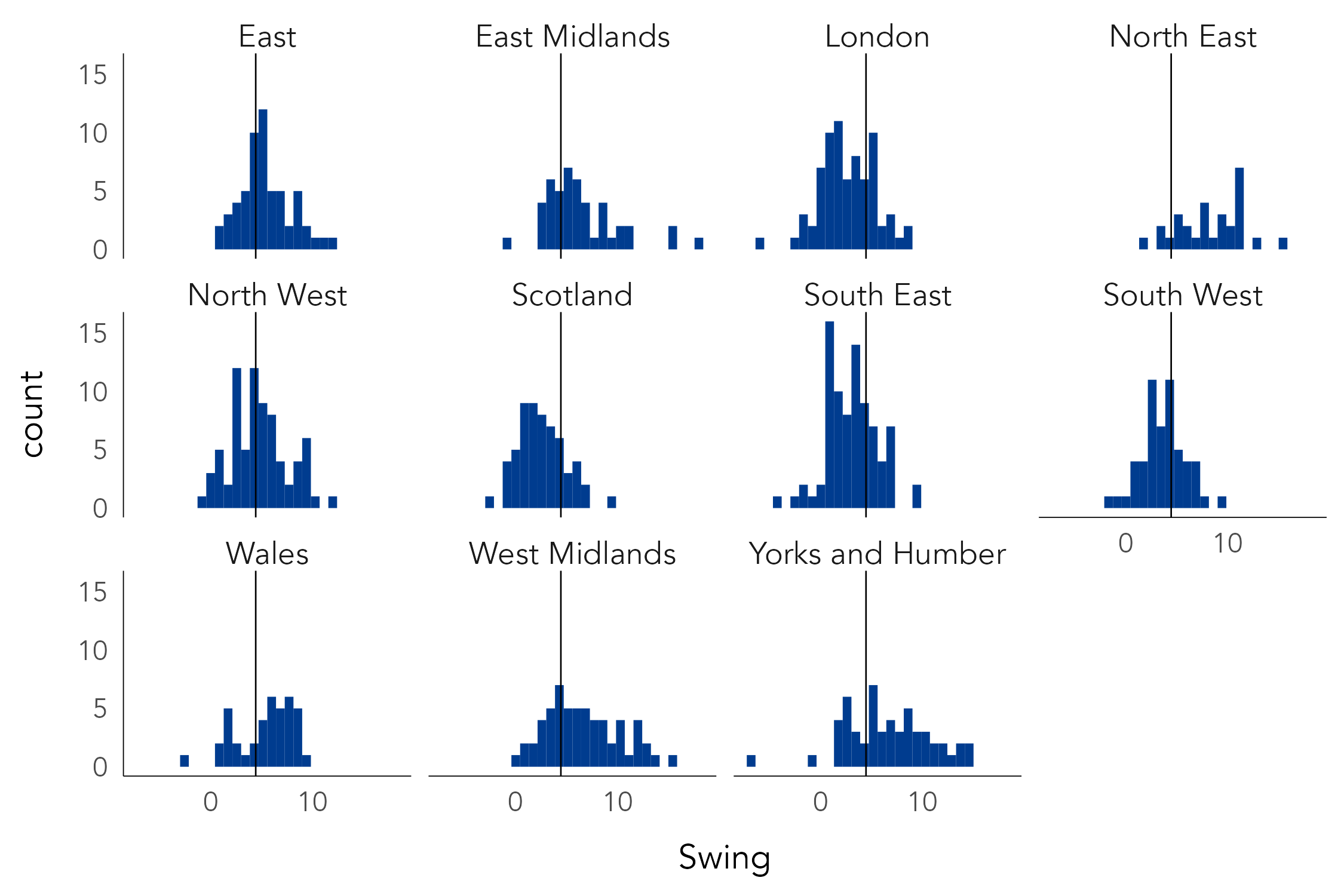
3.3.4 Plot ranks/magnitudes
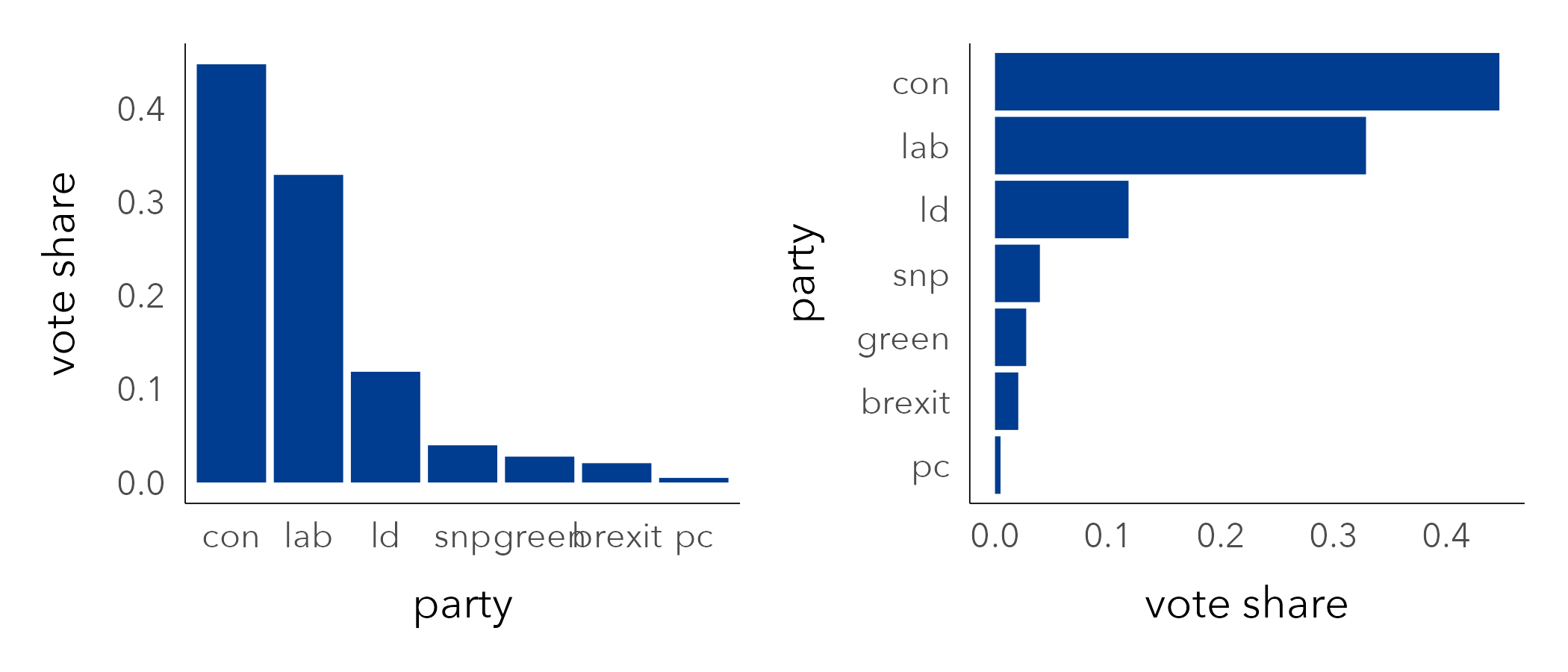
Previously we calculated overall vote shares by political party. We could continue the exploration of votes by region, re-using this code to generate plots displaying vote shares by region, using marks and encoding channels that are suitable for magnitudes.
To generate a bar chart similar to Figure 3.9 the ggplot2 specification would be:
data_gb |>
# The code block summarising vote by party.
<some dplyr code> |>
# Ordinal x-axis (party, reordered), Ratio y-axis (vote_share).
ggplot(aes(x=reorder(party, -vote_share), y=vote_share)) +
geom_col(fill="#003c8f") +
coord_flip()A quick breakdown of the specification:
- Data: This is the summarised data frame in which each row is a political party, and the column describes the vote share recorded for that party.
-
Encoding: We have dropped the call to
mapping=. ggplot2 always looks foraes(), and so we can save on code clutter. In this case we are mappingpartyto the x-axis, a categorical variable made ordinal by the fact that we reorder the axis left-to-right descending onvote_share.vote_shareis mapped to the y-axis – so encoded using bar length on an aligned scale, an effective channel for conveying magnitudes. -
Marks:
geom_col()for generating the bars. -
Setting: Again, we’ve set bar colour to manually selected dark blue. Optionally we add a
coord_flip()layer in order to display the bars horizontally. This makes the category axis labels easier to read and also seems more appropriate for the visual “ranking” of bars.
Faceting by region
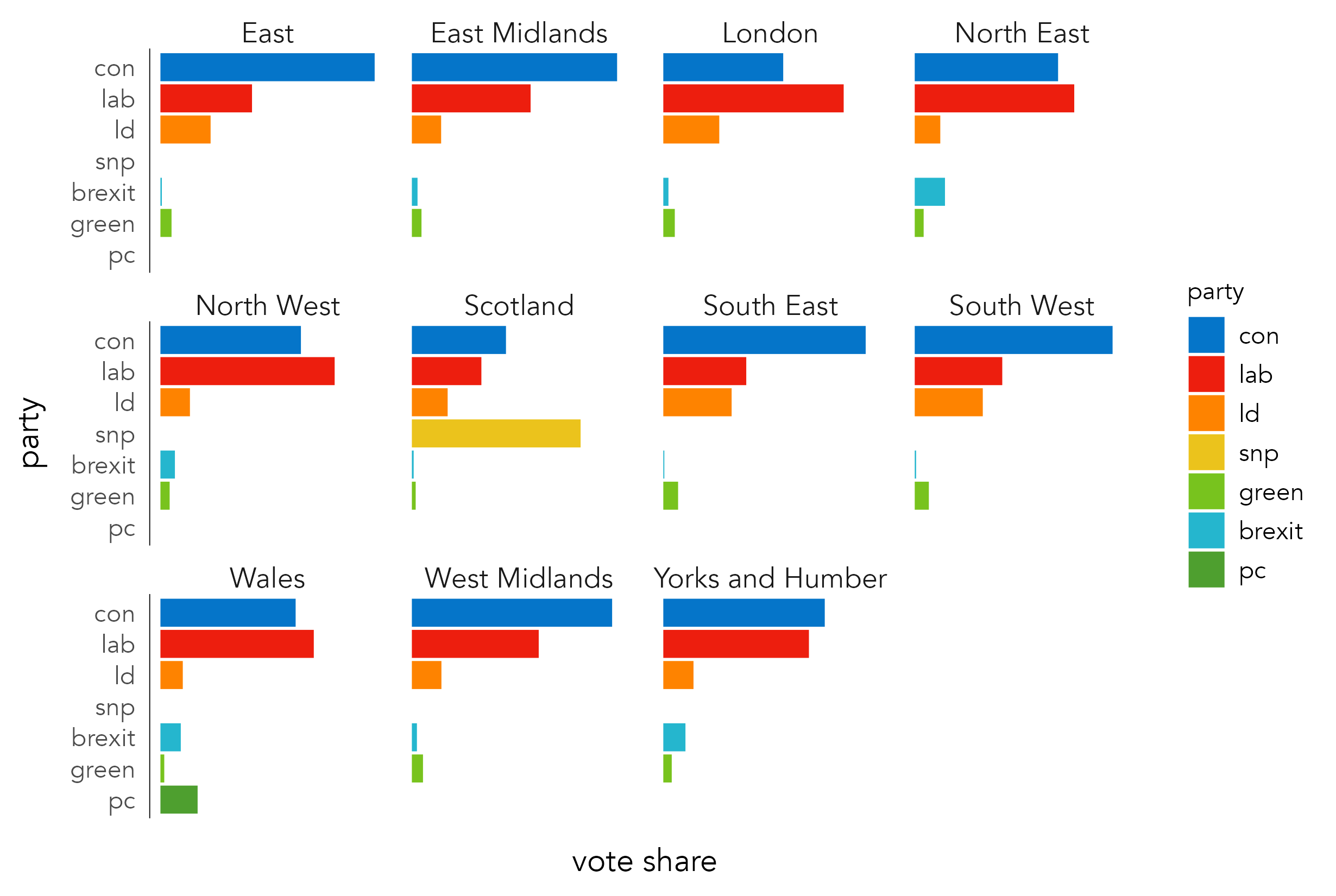
In Figure 3.10 the graphic is faceted by region. This requires an updated staged dataset grouping by vote_share and region and of course a faceting layer (geom_facet(~region)). The graphic is more data-rich, and additional cognitive effort is required in relating the political party bars between different graphical subsets. We can assist this associative task by encoding parties with an appropriate visual channel: colour hue. The ggplot2 specification for this is as you would expect; we add a mapping to geom_col() and pass the variable name party to the fill argument (aes(fill=party)).
data_gb |>
# The code block summarising vote by party and also now region.
<some dplyr code> |>
# To be piped to ggplot2.
ggplot(aes(x=reorder(party, vote_share), y=vote_share)) +
geom_col(aes(fill=party)) +
coord_flip() +
facet_wrap(~region)Trying this for yourself, you will observe that the ggplot2 internals do some thinking for us. Since party is a categorical variable, a categorical hue-based colour scheme is automatically applied. Try passing a quantitative variable (fill=vote_share) to geom_col() and see what happens; a quantitative colour gradient scheme is applied.
Clever as this is, when encoding political parties with colour, symbolisation is important. It makes sense to represent political parties using colours with which they are most commonly associated. We can override ggplot2’s default colour by adding a scale_fill_manual() layer into which a vector of hex codes describing the colour of each political party is passed (party_colours). We also need to tell ggplot2 which element of party_colours to apply to which value of the party variable. In the code below, a staging table is generated summarising vote_share by political party and region. In the final line the party variable is recoded as a factor. You might recall from the last chapter that factors are categorical variables of fixed and orderable values – levels. The call to mutate() recodes party as a factor variable and orders the levels according to overall vote share.
# Generate staging data.
temp_party_shares_region <- data_gb |>
select(
constituency_name, region, total_vote_19,
con_vote_19:alliance_vote_19
) |>
pivot_longer(
cols=con_vote_19:alliance_vote_19,
names_to="party", values_to="votes"
) |>
mutate(party=str_extract(party, "[^_]+")) |>
group_by(party, region) |>
summarise(vote_share=sum(votes, na.rm=TRUE)/sum(total_vote_19)) |>
filter(
party %in% c("con", "lab", "ld", "snp", "green", "brexit", "pc")
) |>
mutate(party=factor(party,
levels=c("con", "lab", "ld", "snp", "green", "brexit", "pc"))
)Next, a vector of objects is created containing the hex codes for the colours of political parties (party_colours).
# Define colours.
con <- "#0575c9"
lab <- "#ed1e0e"
ld <- "#fe8300"
snp <- "#ebc31c"
green <- "#78c31e"
pc <- "#4e9f2f"
brexit <- "#25b6ce"
other <- "#bdbdbd"
party_colours <- c(con, lab, ld, snp, green, brexit, pc)The ggplot2 specification is then updated with the scale_fill_manual() layer:
temp_party_shares_region |>
ggplot(aes(x=reorder(party, vote_share), y=vote_share)) +
geom_col(aes(fill=party)) +
scale_fill_manual(values=party_colours) +
coord_flip() +
facet_wrap(~region)
Grammar of Graphics-backed visualization toolkits
The idea behind visualization toolkits such as ggplot2 is to insert visual approaches into a data scientist’s workflow. Rather than being overly concerned with low-level aspects of drawing, mapping data values to screen coordinates and scaling factors, you instead focus on aspects relevant to the analysis – the variables in a dataset and how they will be encoded and conditioned using visuals. Hadley Wickham talks about a grammar of interactive data analysis, whereby
The process of searching for, defining and inserting manual colour schemes for creating Figure 3.10 might seem inimical to this. There is some reasonably involved
dplyr functions are used to rapidly prepare data for charting before being piped (|>) to ggplot2.The process of searching for, defining and inserting manual colour schemes for creating Figure 3.10 might seem inimical to this. There is some reasonably involved
dplyr and a little regular expression in the data preparation code that you should not be overly concerned with. Having control of these slightly more low-level properties is, though, sometimes necessary even for exploratory analysis, in this case for effecting symbolisation that supports comparison.3.3.5 Plot relationships
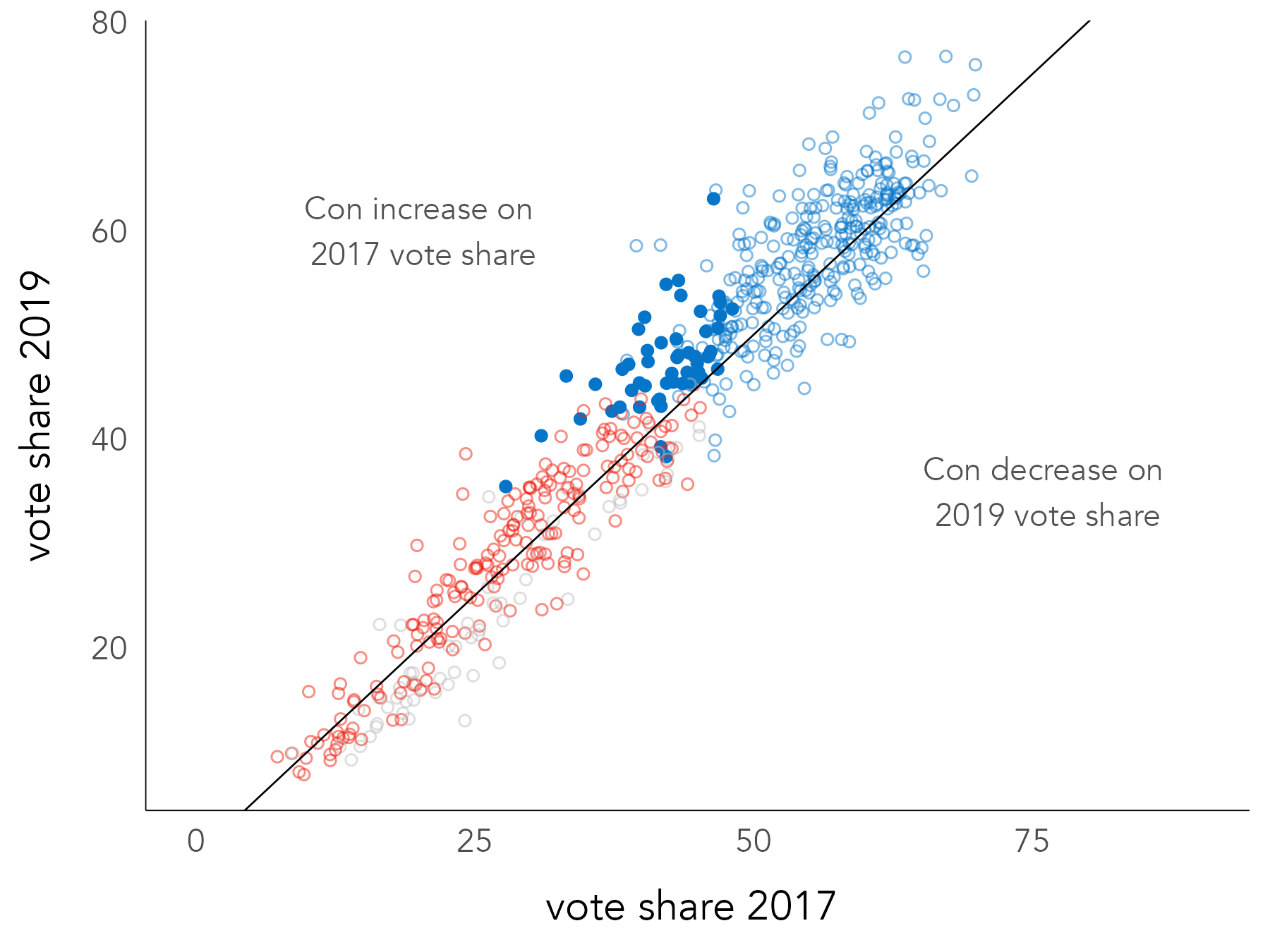
To continue the investigation of change in votes for the major parties between 2017 and 2019, Figure 3.11 contains a scatterplot of Conservative vote share in 2019 (y-axis) against vote share in 2017 (x-axis). The graphic is annotated with a diagonal line. If constituencies voted in 2019 in exactly the same way as 2017, the points would converge on the diagonal. Points above the diagonal indicate a larger Conservative vote share than 2017, those below the diagonal a smaller Conservative vote share than 2017. Points are coloured according to the winning party in 2019, and constituencies that flipped from Labour to Conservative are emphasised using transparency and shape.
The code for generating most of the scatterplot in Figure 3.11 is below.
data_gb |>
mutate(winner_19=case_when(
winner_19 == "Conservative" ~ "Conservative",
winner_19 == "Labour" ~ "Labour",
TRUE ~ "Other"
)) |>
ggplot(aes(x=con_17, y=con_19)) +
geom_point(aes(colour=winner_19), alpha=.8) +
geom_abline(intercept = 0, slope = 1) +
scale_colour_manual(values=c(con,lab,other)) +
...There is little surprising here:
-
Data: The
data_gbdata frame. Values ofwinner_19that are not Conservative or Labour are recoded to Other using a conditional statement. This is to ease and narrow the comparison to the two major parties. -
Encoding: Conservative vote shares in 2017 and 2019 are mapped to the x- and y- axes respectively and
winner_19to colour.scale_colour_manual()is used for customising the colours. -
Marks:
geom_point()for generating the points of the scatterplot;geom_abline()for drawing the reference diagonal.
3.3.6 Plot geography
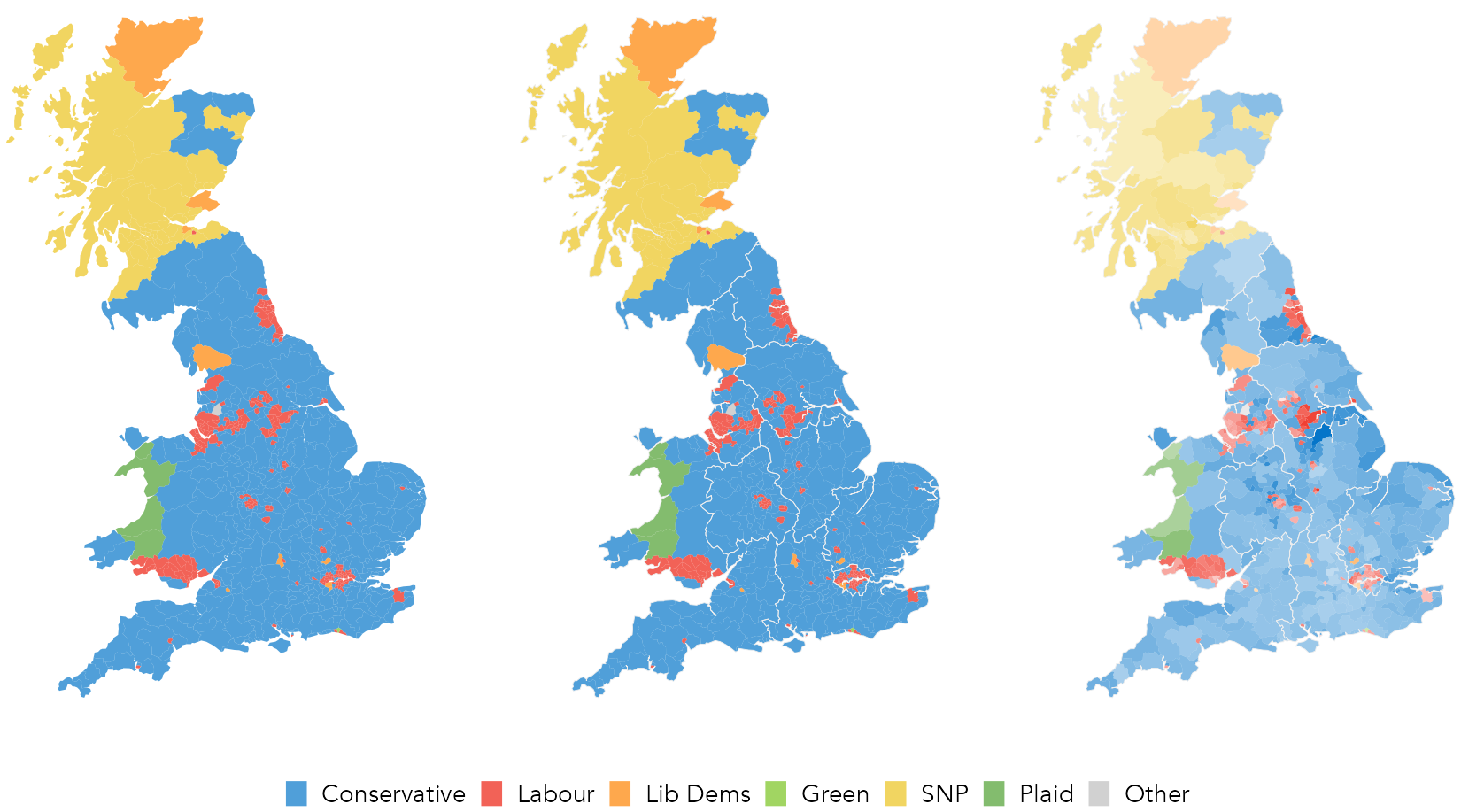
The data graphics above suggest that the composition of Conservative and Labour voting may be shifting. Paying attention to the geography of voting, certainly to changes in voting between 2017 and 2019 elections (e.g. Figure 3.8), may therefore be instructive. We end the technical component to the chapter by generating thematic maps of the results data.
To do this we need to generate a join on the boundary dataset loaded at the start of this technical section (cons_outline):
# Join constituency boundaries.
data_gb <- cons_outline |>
inner_join(data_gb, by=c("pcon21cd"="ons_const_id"))
# Check class.
## [1] "sf" "data.frame"The code for generating the choropleth maps of winning party by constituency in Figure 3.12:
# Recode winner_19 as a factor variable for assigning colours.
data_gb <- data_gb |>
mutate(
winner_19=if_else(winner_19=="Speaker", "Other", winner_19),
winner_19=factor(winner_19, levels=c("Conservative", "Labour",
"Liberal Democrat", "Scottish National Party", "Green",
"Plaid Cymru", "Other"))
)
party_colours <- c(con, lab, ld, snp, green, pc, other)
# Plot map.
data_gb |>
ggplot() +
geom_sf(aes(fill=winner_19), colour="#eeeeee", linewidth=0.01) +
# Optionally add a layer for regional boundaries.
geom_sf(data=. %>% group_by(region) %>% summarise(),
colour="#eeeeee", fill="transparent", linewidth=0.08) +
coord_sf(crs=27700, datum=NA) +
scale_fill_manual(values=party_colours)A breakdown of the ggplot2 spec:
-
Data: Update
data_gbby recodingwinner_19as a factor and defining a named vector of colours to supply toscale_fill_manual(). Note that we also use theparty_coloursobject created for the region bar chart. -
Encoding: No surprises here –
fillaccording towinner_19. -
Marks:
geom_sf()is a special class of geometry. It draws objects using the contents of a simple features data frame’s (Pebesma 2018)geometrycolumn. In this caseMULTIPOLYGON, so read this as a polygon shape primitive. -
Coordinates:
coord_sf– we set the coordinate system (CRS) explicitly. In this case OS British National Grid. -
Setting: Constituency boundaries are subtly introduced by setting the
geom_sf()mark to light grey (colour="#eeeeee") with a thin outline (linewidth=0.01). On the map to the right, outlines for regions are added as anothergeom_sf()layer. Note how this is achieved in the secondgeom_sf(). Thedata_gbdataset initially passed to ggplot2 (identified by the.mark) is collapsed by region (withgroup_by()andsummarise()) and in the background the boundaries ingeometryare aggregated by region.
Preparing data for plotting
A general point from the code blocks in this chapter is that proficiency in dplyr and tidyr is a necessity. Throughout the book you will find yourself needing to calculate new variables, recode variables and reorganise data frames before handing them over to ggplot2 for plotting.
In the third map of Figure 3.12 the transparency (alpha) of filled constituencies is varied according to the Swing variable. This demonstrates that constituencies swinging most dramatically for Conservative (darker colours) are in the midlands and North of England and not in London and the South East. The pattern is nevertheless a subtle one; transparency (colour luminance / saturation) is not a highly effective visual channel for encoding quantities.
It may be worth applying the same encoding to Butler two-party swing as that used in the Washington Post graphic when characterising Republican-Democrat swing in 2016 US Elections (e.g. Beecham 2020). This can be achieved by simply adding another ggplot2 layer, though the code is a little more involved. ggplot2’s geom_spoke() primitive draws line segments parameterised by a location (x- y- position) and angle. With this we can encode constituencies with | marks that angle to the right / where the constituency swings towards Conservative and to the left where it swings towards Labour \. This encoding better exposes the pattern of constituencies forming Labour’s “red wall” in the north of England, as well as parts of Wales and the Midlands flipping to Conservative.
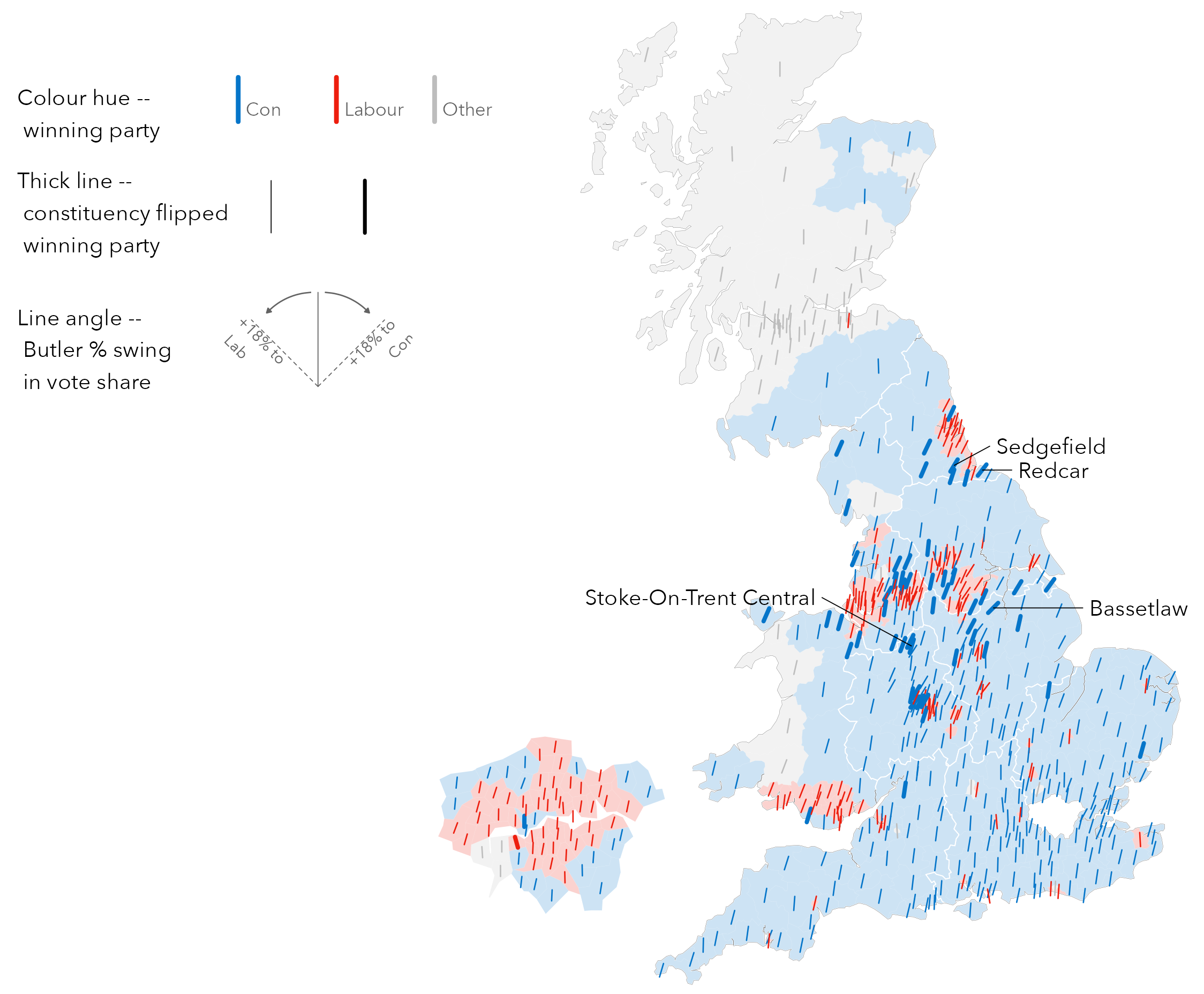
The ggplot2 specification:
# Find the maximum Swing values to pin the min and max angles to.
max_shift <- max(abs(data_gb |> pull(swing_con_lab)))
min_shift <- -max_shift
# Re-define party_colours to contain just three values: hex codes for
# Conservative, Labour and Other.
party_colours <- c(con, lab, other)
names(party_colours) <- c("Conservative", "Labour", "Other")
# Plot Swing map.
data_gb |>
mutate(
is_flipped=seat_change_1719 %in%
c("Conservative gain from Labour",
"Labour gain from Conservative"),
elected=if_else(!winner_19 %in% c("Conservative", "Labour"), "Other",
as.character(winner_19)),
swing_angle=
get_radians(map_scale(swing_con_lab,min_shift,max_shift,135,45)
)
) |>
ggplot()+
geom_sf(aes(fill=elected), colour="#636363", alpha=.2, linewidth=.01)+
geom_spoke(
aes(x=bng_e, y=bng_n, angle=swing_angle, colour=elected,
linewidth=is_flipped),
radius=7000, position="center_spoke"
)+
coord_sf(crs=27700, datum=NA)+
scale_linewidth_ordinal(range=c(.2,.5))+
scale_colour_manual(values=party_colours)+
scale_fill_manual(values=party_colours)A breakdown:
-
Data:
data_gbis updated with a Boolean (TRUE/FALSE) variable identifying whether or not the constituency flipped between successive elections (is_flipped), and a variable simplifying the party elected to either Conservative, Labour or Other.swing_anglecontains the angles used to orient the line marks. A convenience function (map_scale()) pins the maximum swing values to 45 degrees and 135 degrees – respectively max swing to the right, Conservative and max swing to the left, Labour. -
Encoding:
geom_sf()is again filled by elected party. This encoding is made more subtle by adding transparency (alpha=.2).geom_spoke()is mapped to the geographic centroid of each Constituency (bng_e- easting,bng_n- northing), coloured on elected party, sized on whether the constituency flipped its vote and tilted or angled according to theswing_anglevariable. -
Marks:
geom_sf()for the constituency boundaries,geom_spoke()for the angled line primitives. -
Scale:
geom_spoke()primitives are sized to emphasise whether constituencies have flipped. The size encoding is censored to two values withscale_linewidth_ordinal(). Passed toscale_colour_manual()andscale_fill_manual()is the vector ofparty_colours. -
Coordinates:
coord_sf– the CRS is OS British National Grid, so we define constituency centroids using easting and northing planar coordinates. -
Setting: The
radiusofgeom_spoke()lines is a sensible default arrived at through trial and error, itspositionset using a newly createdcenter_spokeclass.
There are helper functions that must also be run to execute the ggplot2 code above correctly. In order to position lines using geom_spoke() centred on their x- y- location, we need to create a custom ggplot2 subclass. Details are in the 03-template.qmd file. Again, this is somewhat involved for a chapter introducing ggplot2 for analysis. Nevertheless, hopefully you can see from the plot specification above that the principles of mapping data to visuals can be implemented straightforwardly in ggplot2: line marks for constituencies (geom_spoke()), positioned in x and y according to British National Grid easting and northings and oriented (angle) according to two-party Swing.
Dot-density maps
A common design challenge when presenting population data spatially is to accurately reflect geography at the same time as the quantitative outcome of interest – in this case, the location and shape of constituencies versus their associated vote sizes. You may be familiar with cartogram layouts used in electoral analysis. They are maps that distort geographic space in order to size constituencies according to the voting population rather than their physical area. Dot-density maps also convey absolute numbers of votes but in a way that preserves geography. In the example below, each dot represents 1,000 votes for a given party – Conservative, Labour, Other – and dots are positioned in the constituencies from which those votes were made. Dots therefore concentrate in population-dense areas of the country.
The difficulty in generating dot-density maps is not wrangling ggplot2, but in preparing data to be plotted. We need to create a randomly located point within a constituency’s boundary for every thousand votes that are made there. R packages specialised to dot-density maps provide functions for doing this, but it is quite easy to achieve using the sorts of functional and tidyverse-style code introduced throughout this book. We include the code for Figure 3.14 directly below the plot. While compact, there are some quite advanced functional programming concepts (in the use of purrr::map()) that we do not explain. These concepts are in fact covered in some detail and with proper description in later chapters of the book.
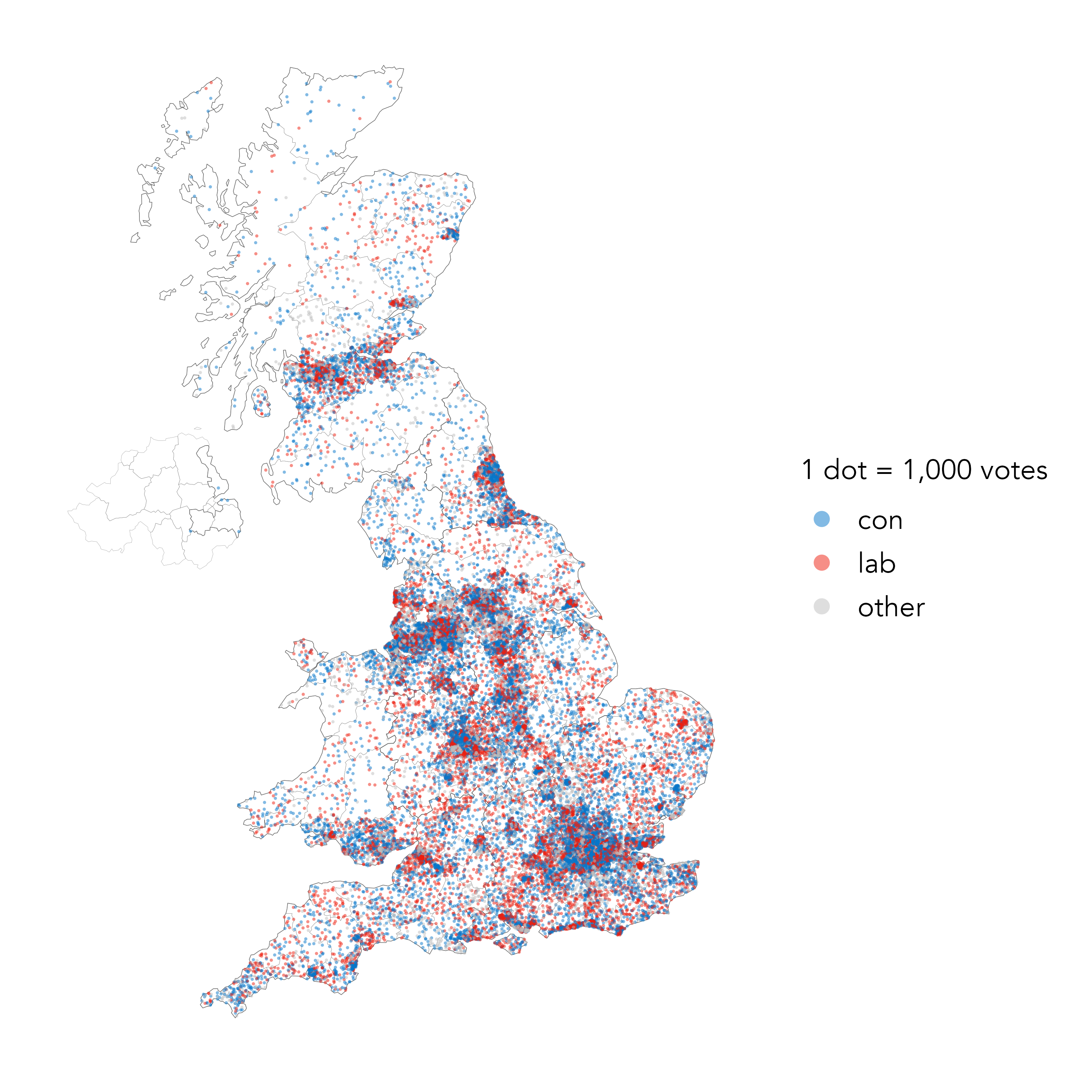
Code
# Collect 2019 GE data from which dots are approximated.
vote_data <- bes_2019 |>
filter(ons_const_id!="S14000051") |>
mutate(
other_vote_19=total_vote_19-(con_vote_19 + lab_vote_19)
) |>
select(
ons_const_id, constituency_name, region, con_vote_19,
lab_vote_19, other_vote_19
) |>
pivot_longer(
cols=con_vote_19:other_vote_19,
names_to="party", values_to="votes"
) |>
mutate(
party=str_extract(party, "[^_]+"),
votes_dot=round(votes/1000,0)
) |>
filter(!is.na(votes_dot))
# Sample within constituency polygons.
# This might take a bit of time to execute.
start_time <- Sys.time()
sampled_points <-
cons_outline |>
select(geometry, pcon21cd) |> filter(pcon21cd!="S14000051") |>
inner_join(
vote_data |> group_by(ons_const_id) |>
summarise(votes_dot=sum(votes_dot)) |> ungroup(),
by=c("pcon21cd"="ons_const_id")
) |>
nest(data=everything()) |>
mutate(
sampled_points=map(data,
~sf::st_sample(
x=.x, size=.x$votes_dot, exact=TRUE, type="random"
) |> st_coordinates() |>
as_tibble(.name_repair=~c("east", "north"))),
const_id=map(data, ~.x |> st_drop_geometry() |>
select(pcon21cd, votes_dot) |> uncount(votes_dot))
) |>
unnest(-data) |>
select(-data)
end_time <- Sys.time()
end_time - start_time
point_votes <- vote_data |> select(party, votes_dot) |>
uncount(votes_dot)
sampled_points <- sampled_points |> bind_cols(point_votes)
# Plot sampled points.
party_colours <- c(con, lab, other)
sampled_points |>
ggplot() +
geom_sf(
data=cons_outline, fill="transparent",
colour="#636363", linewidth=.03
) +
geom_sf(data=cons_outline |>
inner_join(vote_data, by=c("pcon21cd"="ons_const_id")) |>
group_by(region) |> summarise(),
fill="transparent", colour="#636363", linewidth=.1) +
geom_point(
aes(x=east,y=north, fill=party, colour=party),
alpha=.5, size=.6, stroke=0
)+
scale_fill_manual(values=party_colours, "1 dot = 1,000 votes")+
scale_colour_manual(values=party_colours, "1 dot = 1,000 votes")+
guides(colour=guide_legend(override.aes=list(size=3)))+
theme_void()
3.4 Conclusions
Visualization design is ultimately a process of decision-making. Data must be filtered and prioritised before being encoded with marks, visual channels and symbolisation. The most successful data graphics are those that expose structure, connections and comparisons that could not be achieved easily via other, non-visual means. This chapter has introduced concepts – a vocabulary, framework and empirically-informed guidelines – that help support this decision-making and that underpin modern visualization toolkits, ggplot2 especially. Through an analysis of UK 2019 General Election data, we have demonstrated how these concepts can be applied in a real data analysis.
3.5 Further Reading
For a primer on visualization design principles:
- Munzner, T. 2014. “Visualization Analysis and Design”, Boca Raton, FL: CRC Press.
A paper presenting evidence-backed guidelines on visualization design, aimed at applied researchers:
- Franconeri S. L., Padilla L. M., Shah P., Zacks J. M., Hullman J. (2021). “The science of visual data communication: What works”. Psychological Science in the Public Interest, 22(3), 110–161. doi: 10.1177/15291006211051956.
For an introduction to ggplot2 and its relationship with Wilkinson’s (1999) grammar of graphics:
- Wickham, H., Çetinkaya-Rundel, M., Grolemund, G. 2023, “R for Data Science, 2nd Edition”, Sebastopol, CA: O’Reilly.
- Chapters 1, 9.
Excellent paper looking at consumption and impact of election forecast visualizations:
- Yang, F. et al. 2024. “Swaying the Public? Impacts of Election Forecast Visualizations on Emotion, Trust, and Intention in the 2022 U.S. Midterms.” IEEE Transactions on Visualization and Computer Graphics, 30(1), 23–33. doi: 10.1109/TVCG.2023.3327356.